Engineering Behind Bucket0
Bucket0 is a private cloud storage platform I built. It has an S3 bucket manager, team collaboration, an S3-compatible API, and AgentBucket, a storage-on-API layer for AI agents. The whole thing runs on a single VPS for under $8 a month.
That is not a limitation. It is an architecture. And this post walks through the engineering decisions that make it possible.
The $8 Question#
Most SaaS products hit triple-digit infrastructure bills before their first paying customer. Bucket0 runs its entire production stack for under $8 a month.
This isn't an accident.
Every engineering decision in Bucket0 was filtered through a simple question: can we avoid paying for this? Not by cutting corners, but by choosing the right layer to solve each problem. The answer, surprisingly often, was to push work to the browser, pick vendors with aligned pricing models, and write a little more code instead of adding another managed service.
The Stack That Costs Almost Nothing#
Here's where the money actually goes:
| Layer | Choice | Monthly Cost |
|---|---|---|
| Compute | Single VPS, Docker, Bun runtime | ~$5-$7 |
| Database | Serverless PostgreSQL (free tier) | $0 |
| Object Storage | Vendor with zero egress fees | ~$1-$2 |
| Auth | Managed auth provider (free tier) | $0 |
| Billing | SaaS billing platform (free tier) | $0 |
| SSL/TLS | Auto-renewing certificates via Caddy | $0 |
| Rate Limiting | In-memory, no external service | $0 |
| PDF/Image Processing | Client-side, runs in the browser | $0 |
| Total | ~$8 |
No Kubernetes. No Redis. No message queues. No serverless compute markup. The entire application, including API, file processing, background jobs, and thumbnail generation, runs in a single Docker container on a budget VPS.
The trick isn't minimalism. It's knowing which problems are expensive to solve in the wrong place and free to solve in the right one.
The Storage Vendor#
The single most important infrastructure decision was the object storage vendor. Traditional cloud storage charges per gigabyte of egress. Every file download costs money. For a storage platform where users repeatedly access their files, egress fees would dominate the bill.
Bucket0 uses a vendor with zero egress fees. Downloads are free. Uploads are free below a generous threshold. The only cost is storage itself and API operations (pennies per million requests). This changes the entire economics of the platform: serving files to users is no longer a cost center.
This also means features like file previews, thumbnail loading, and share link streaming don't create anxiety about bandwidth bills. When egress is free, you can be generous with features that read data.
A Single Container Instead of a Platform#
Bucket0 runs as a single Docker container on a VPS with 4 vCPUs, 8GB of RAM, and 40GB of disk. The application uses Next.js with standalone output. The entire server, including API routes, static assets, and server-side rendering, is a single process.
The runtime is Bun instead of Node.js. Faster startup, lower memory footprint, same JavaScript. Steady-state memory usage stays well under a gigabyte despite having 8GB available, so most of that headroom is there for spikes during image processing (sharp and ffmpeg are hungry).
Caddy sits in front as a reverse proxy, handling HTTPS termination with automatic Let's Encrypt certificates, HTTP/2, and HTTP/3. Zero certificate management, zero renewal scripts, zero cost.
This architecture has an obvious scaling ceiling. One box, one process. But that ceiling is surprisingly high for a storage platform where the heavy lifting (object storage, database) is handled by external services. The VPS mostly coordinates: authenticate the user, check quota, generate a presigned URL, let the client upload directly to the vendor. The actual bytes never touch the server during uploads.
The Database That Sleeps#
The PostgreSQL database runs on a serverless provider that automatically suspends after a period of inactivity. When no queries are hitting it, the database shuts down. When a request comes in, it cold-starts in milliseconds.
For a storage platform, this is ideal. Database operations are bursty. A flurry of queries during file uploads and page loads, then silence. The serverless model means Bucket0 pays nothing during the quiet hours. The free tier provides enough storage and compute for the current scale, and the HTTP-based connection protocol (not traditional TCP pooling) eliminates the overhead of maintaining persistent connections from the VPS.
Encryption#
Chunked AES-GCM#
The naive approach to file encryption is straightforward: read the whole file into memory, encrypt it, upload the ciphertext. This works great until someone uploads a 2GB video and your server process gets OOM-killed.
Bucket0 uses chunked AES-GCM encryption with a custom binary file format. Every file is split into 8MB chunks, and each chunk is independently encrypted with its own initialization vector and authentication tag. AES-GCM is the industry standard, the same authenticated encryption used by TLS, SSH, and every major cloud provider. It provides both confidentiality and integrity in a single pass, with hardware acceleration on modern CPUs.
The on-disk format:
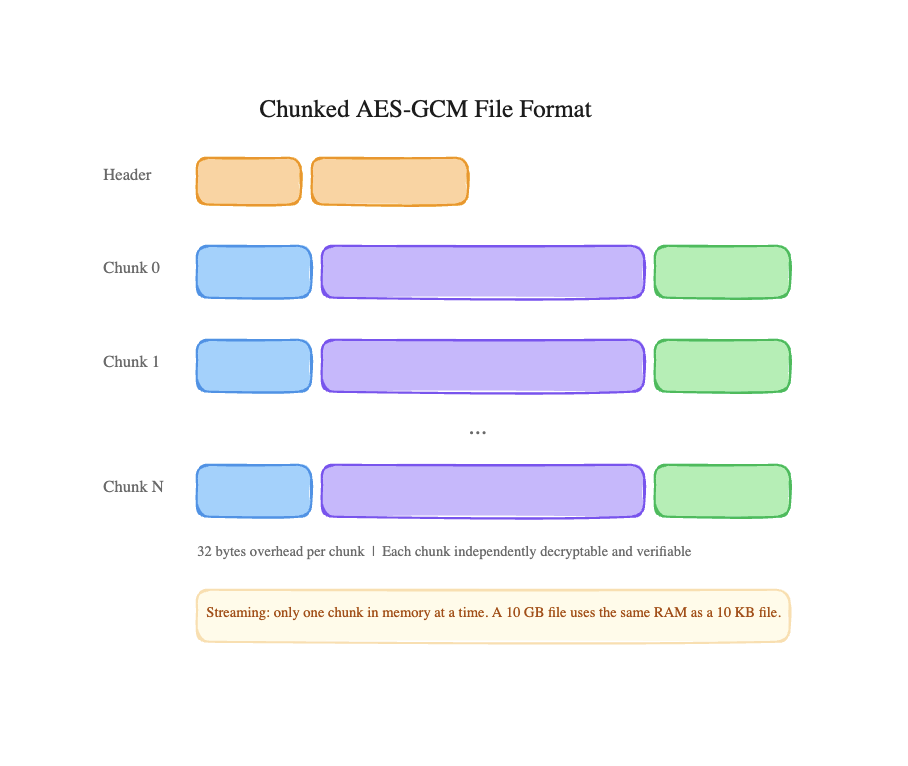
The overhead is 32 bytes per chunk, negligible for 8MB chunks. But the design unlocks something powerful: streaming. The encryption and decryption pipelines use Node.js Transform streams, so the server never needs to hold more than one 8MB chunk in memory at a time. A 10GB file uses the same memory as a 10KB file.
Each chunk being independently authenticated also means tamper detection is granular. If a single chunk gets corrupted in storage, only that chunk fails verification. The rest of the file is still valid and readable. The version byte in the header allows the format to evolve without breaking existing files.
Not everything benefits from encryption though. Archives (.zip, .7z, .tar.gz) are already compressed and often publicly distributed. Executables and disk images are typically signed. Encrypting these burns CPU for no real security gain, so Bucket0 maintains a skip list. Certain file types bypass encryption entirely. It's the kind of decision that feels wrong until you see the CPU graphs.
Range Requests on Encrypted Files#
Here's a problem that sounds impossible at first: a client sends a standard HTTP Range: bytes=1000-5000 header. But the file on the vendor is encrypted. You can't just fetch bytes 1000-5000 of the ciphertext. That maps to the middle of some encrypted chunk, and decrypting half a chunk produces garbage.
The solution is a coordinate translation layer. Given a plaintext byte range, Bucket0 calculates which encrypted chunks contain that range, fetches only those chunks from the vendor, decrypts them, and slices out exactly the bytes the client asked for.
Plaintext range: bytes 1000-5000
→ Maps to chunk index 0 (plaintext bytes 0-8388607)
→ Encrypted chunk 0 lives at vendor offset 5 through 8388644
→ Fetch bytes=5-8388644 from vendor
→ Decrypt chunk 0
→ Slice plaintext bytes 1000-5000 from the result
→ Return 4001 bytes to client
This means media players can seek through encrypted video files, browsers can resume interrupted downloads, and PDF viewers can request specific pages, all without downloading and decrypting the entire file. The system handles files that span multiple chunks, stitching the decrypted output from several chunk boundaries.
Two layout modes exist: one with a 5-byte header (for standard uploads) and one without (for multipart uploads where the header would break vendor part-size alignment). The range calculator accounts for both transparently.
Credential Encryption#
Users can connect their own S3-compatible storage to Bucket0. This means Bucket0 stores their access keys. These credentials are encrypted with AES-256-GCM, a higher key strength than file content encryption.
The reasoning: a leaked file is one file. A leaked credential is access to an entire bucket, potentially containing years of data. The encryption strength is proportional to the blast radius of compromise.
Both the access key ID and secret access key share a single IV but get separate authentication tags, which are concatenated for storage. One row in the database, one IV, one combined tag. Compact but fully authenticated.
The Upload Pipeline#
A file upload that fails halfway through can leave the system in an inconsistent state: storage quota consumed but no file to show for it, or a file stored but no database record pointing to it. Bucket0 prevents this with a three-phase upload initialization, and the ordering of the phases turned out to be critical.
Phase 1: File Slot Acquisition. Before anything touches the database or the vendor, an in-memory tracker reserves a slot for this specific file. If another request tries to upload the same file concurrently, it gets a 409 Conflict. The slot starts in a __pending__ state, a placeholder that says "someone is working on this."
Phase 2: Atomic Quota Reservation. A single SQL statement both checks the user's remaining quota and reserves space, atomically:
UPDATE users
SET storageUsage = storageUsage + :size,
fileCount = fileCount + :count
WHERE id = :userId
AND (storageUsage + :size) <= maxStorageBytes
If the user doesn't have enough space, the affected rows count is zero, the slot from Phase 1 is released, and the client gets a clear error. No partial state.
Phase 3: Vendor Upload Creation. Only after quota is secured does the system create the actual multipart upload on the vendor. The pending slot is upgraded with the real upload ID.
The key insight is the ordering: slot before quota before vendor. If you reserve quota first and then discover a duplicate upload, you'd have to reverse the quota change. If you create the vendor upload first and then discover a quota violation, you'd have an orphaned multipart upload on the vendor. By acquiring the slot first (a cheap in-memory operation), the expensive database and network calls only happen when they're guaranteed to be needed.
Uploads die. Browsers close, networks drop, users give up. The tracker runs periodic cleanup: any upload older than one hour is considered abandoned. Its quota reservation is rolled back, and the vendor's multipart upload is aborted. The tracker logs stats every 10 seconds when uploads are active. Not for debugging, but because abandoned uploads silently eating quota is the kind of bug that takes weeks to notice.
Dual Quota Tracking#
Teams in Bucket0 share storage from the team owner's plan. A team doesn't get its own quota allocation. The owner's plan is the ceiling. This creates an interesting bookkeeping problem: you need to track how much storage a team uses (for display and analytics), but the authoritative limit check must happen against the owner's plan.
The solution is dual writes: every upload updates both the owner's users.storageUsage (the source of truth) and the team's teams.storageUsage (for display). The owner update is conditional and enforces the quota limit. The team update is unconditional. It's a counter, not a gate.
This means the two values can theoretically diverge if the second write fails after the first succeeds. That's acceptable because the plan-enforced quota is always the gate. The team counter is informational. Prioritizing correctness of the constraint over consistency of the display is the right tradeoff when real money (plan limits) is involved.
Thumbnails#
Thumbnail generation is intentionally decoupled from the upload flow. When a file upload completes, thumbnail generation is kicked off asynchronously and does not block the upload response. If thumbnail generation fails, the upload still succeeds. The user sees a generic file icon instead of a preview. Nobody's upload fails because GraphicsMagick had a bad day.
The interesting part is how little data the thumbnail pipeline actually needs:
- Images: 1 encrypted chunk (~8MB) from the vendor. Almost always enough for metadata extraction and thumbnail rendering.
- Videos: 2 encrypted chunks (~16MB). Enough to extract the first frame using ffmpeg, even for high-bitrate video.
- PDFs: 1 encrypted chunk (~8MB). The first page is rasterized at 150 DPI using GraphicsMagick and Ghostscript.
For a 4GB video file, the thumbnail generator fetches 16MB, less than 0.5% of the file. This is only possible because of the chunked encryption format: you can fetch and decrypt individual chunks without touching the rest of the file.
Output is standardized: WebP at 85% quality, max 400x400 pixels, with aspect-ratio-aware sizing. Near-square images (ratio between 0.9 and 1.1) get cropped to fill. Landscape and portrait images scale proportionally within the 400px bound. Small details, but they make a grid of thumbnails look intentional rather than chaotic.
The generated thumbnails are cached with Cache-Control: public, max-age=31536000, immutable, a one-year browser cache. Once a thumbnail is generated and delivered, it never hits the vendor again.
Client-Side Document Tools#
Bucket0 includes over 20 free PDF tools and a suite of image tools like merge, split, extract, protect, unlock, sign, redact, watermark, resize, compress, and convert. The curious engineering decision: none of these touch the server.
Every operation runs entirely in the browser. Files are loaded via the File API, processed using client-side libraries, and the result is downloaded directly. The server never sees the file contents.
This started as a privacy guarantee. Users processing sensitive legal or medical documents shouldn't have to trust the server. But it turned out to be one of the most important cost decisions in the entire architecture. If PDF processing ran server-side, the VPS would need to handle CPU-intensive document manipulation for every user simultaneously. By pushing this to the browser, Bucket0 gets unlimited parallel processing capacity for free. Every user's device is their own compute node.
The tradeoff is browser memory. A merge of twenty 50MB PDFs means a gigabyte of ArrayBuffers in the browser's heap. The tools enforce a 20-file limit for merges, a practical ceiling that keeps most browsers happy while covering the vast majority of real-world use cases.
Caching and Cost Control#
When your infrastructure budget is under $8, every unnecessary request to the vendor is a micro-expense and a latency penalty. Bucket0 treats caching not as a performance optimization but as a cost control mechanism.
ETags for conditional requests. Every file view and share link stream includes an ETag derived from the file key and last-modified timestamp. When a browser re-requests a file it already has, the server responds with 304 Not Modified. No vendor fetch, no decryption, no bandwidth. For files that are viewed repeatedly (shared links, team files), this eliminates the majority of vendor reads.
Aggressive thumbnail caching. Thumbnails are immutable once generated (they change only if the file changes). A one-year cache header means the browser never re-requests a thumbnail after the first load. For a dashboard showing 50 files, this turns 50 vendor requests per page load into zero after the first visit.
Presigned URLs for direct uploads. The server never handles upload bytes. It generates a time-limited presigned URL, and the client uploads directly to the vendor. This eliminates the server as a bandwidth bottleneck and removes the need for a beefier VPS to handle concurrent upload streams.
Rate Limiting Without Redis#
Bucket0 uses an in-memory rate limiter: a Map with a cleanup sweep every five minutes. No Redis, no Upstash, no external dependency.
This is a deliberate choice. An in-memory rate limiter has zero latency overhead, zero network calls, and zero infrastructure cost. The tradeoff is that it resets on deploy and doesn't share state across server instances. For a single-container deployment, this is a non-issue.
The system ships with 10 pre-configured rate limiters, each tuned for its specific use case:
| Endpoint | Limit | Why |
|---|---|---|
| File upload | 100/min | Prevents storage abuse |
| Password change | 3/hour | Brute-force protection |
| Checkout | 5/min | Prevents billing system abuse |
| Share link stream | 30/min per IP | Prevents bandwidth abuse on public links |
| S3 connection test | 15/min | Prevents credential-spray attacks |
| Contact form | 5/hour per IP | Spam prevention |
Every rate-limited response includes X-RateLimit-* headers so clients can implement backoff without guessing. When the architecture needs multiple instances, the rate limiter is the one component with a clear migration path to Redis, but not before it's needed.
Small Design Decisions#
The 5-second undo window. Delete operations don't show a confirmation dialog for single files. Instead, the file immediately "disappears" from the UI, and a toast appears with an undo button. The actual deletion request fires after a 5-second window. Pending deletes are held in React state. During the window, the file is hidden from the UI but untouched on the vendor. If the user clicks undo, the pending state clears and the file reappears instantly. Bulk deletes (multiple files) do show a confirmation modal before entering the undo window. The threshold between "probably a mistake" (one file) and "probably intentional" (many files) turns out to be exactly one.
Guard functions that return null on success. Most permission-checking middleware returns the user or throws on failure. Bucket0's route helpers do something unusual: they return null on success and a response on failure.
const denied = await requireTeamPermission(teamId, userId, "canUpload");
if (denied) return denied; // 403 response
// Permission granted, continue...
This pattern looks odd at first, but it composes well. Multiple permission checks can run in parallel with Promise.all, and the route handler can short-circuit on the first non-null result. It also avoids try-catch blocks for flow control, which is a common criticism of exception-based middleware patterns.
The globalThis trick. Next.js development mode reloads modules on every file save. This is great for iteration speed, terrible for in-memory state. The chunked upload tracker, which holds active upload metadata, slot reservations, and quota bookkeeping, would be wiped clean on every code change, orphaning active uploads during development.
const g = globalThis as unknown as { tracker: Tracker | undefined };
export const tracker = g.tracker ?? new Tracker();
if (process.env.NODE_ENV !== "production") {
g.tracker = tracker;
}
In production, this is a normal module-level singleton. In development, the instance survives HMR because globalThis persists across module reloads. The NODE_ENV guard ensures the globalThis reference is never set in production, where it would prevent garbage collection of the module.
Why This Architecture Works (and When It Won't)#
The $8/month architecture works because of a specific set of conditions:
- Object storage is the heavy lifter. File bytes flow between the client and the vendor, never through the server. The VPS is a coordinator, not a pipeline.
- Egress is free. The storage vendor doesn't charge for downloads. This single pricing decision makes the entire model viable.
- Processing is client-side. PDF and image tools run in the browser. The server's CPU is reserved for encryption, thumbnail generation, and API logic.
- The database sleeps. Serverless PostgreSQL with auto-suspend means zero cost during idle hours.
- One instance is enough. No load balancer, no service mesh, no container orchestration. A single process handles everything.
This architecture will need to evolve when any of these conditions change: multi-region deployment, sustained high-concurrency workloads, or features that require server-side document processing. The code is structured to make those transitions straightforward. The rate limiter has a Redis migration path, the upload tracker could move to a shared store, and the VPS could be replaced with container orchestration.
But the point isn't that this architecture scales to a million users. The point is that it scales to the first thousand without spending a dollar more than necessary. The most expensive infrastructure is the infrastructure you pay for before you need it.
The interesting engineering in Bucket0 isn't any single feature. It's how the constraints interact. Chunked encryption enables range requests, which enables efficient thumbnail generation, which runs asynchronously so it doesn't block the upload flow, which uses atomic quota reservation so failures can be rolled back cleanly. Each decision creates the conditions for the next one.
Most of the hard problems weren't in the "what" but in the "in what order." The three-phase upload exists because the ordering of slot acquisition, quota reservation, and vendor upload creation determines whether failure modes are recoverable. The dual quota tracking works because the team counter is explicitly non-authoritative. The skip-encryption list exists because sometimes the most secure thing to do is nothing.
And the $8/month budget? It's not a constraint that limits the engineering. It's a constraint that improves it. When you can't throw money at a problem, you have to actually solve it. The result is a system with less moving parts, fewer failure modes, and a cost structure that doesn't punish growth.
Good infrastructure disappears. When a user drags a file into Bucket0 and sees a thumbnail appear seconds later, they shouldn't be thinking about chunked AES-GCM or atomic SQL expressions or how much the server costs. They should be thinking about whatever they were actually working on.
That's the goal.
stay updated.
It's free! Get notified instantly whenever a new post drops. Stay updated, stay ahead.